Optimization in Machine learning
This is an auxiliar tutorial that could help students to grasp basic concepts on optimization and calculus for Machine Learning. Optimization is an omni-present concept that
we usually employ in ML when we want to compute a good model given some data $\mathbf{D}$ for a specific task $T$. Usually, we introduce an error function $L$ and we want to find optimal parameters $\mathbf{w}$ and $b$ that minimize this error function. For example, in the case of linear regression, this function is the Mean Square Error and we would like to find parameters that minimize this error MSE.
We will start this tutorial from the basics with explaining what the concept of function is and how can we use it in our domain. Then, we will introduce the concept of a loss function and the basics of how to find minimum or maximum of a function using optimization principles. Note: In this tutorial, we will make use of the simple univariate case for regression (meaning that the input $x \in \mathbb{R}$ is a single-value variable).
Functions
Central to Machine learning to mathematics and this chapter is the concept of a function. A function $f$ is a quantity that relates two quantities to each other. We can think of the first quantity as the input and the second quantity as the output. We can use the metaphor for a function as a system. Formally, we can define a function mathematically as:
\[f:x \rightarrow y\]with
\[f : \mathbb{R} \to \mathbb{R}, \quad x \mapsto y\]or otherwise we can write
\[y = f(x)\]As $\mathbb{R}$ we define the space of all real numbers. Please note that the function between input and output in our previous notation, we can say that maps input from the $x \in \mathbb{R}$ to $y \in \mathbb{R}$. So the input is a real value and the output is a real value. This is visualized in the following image:
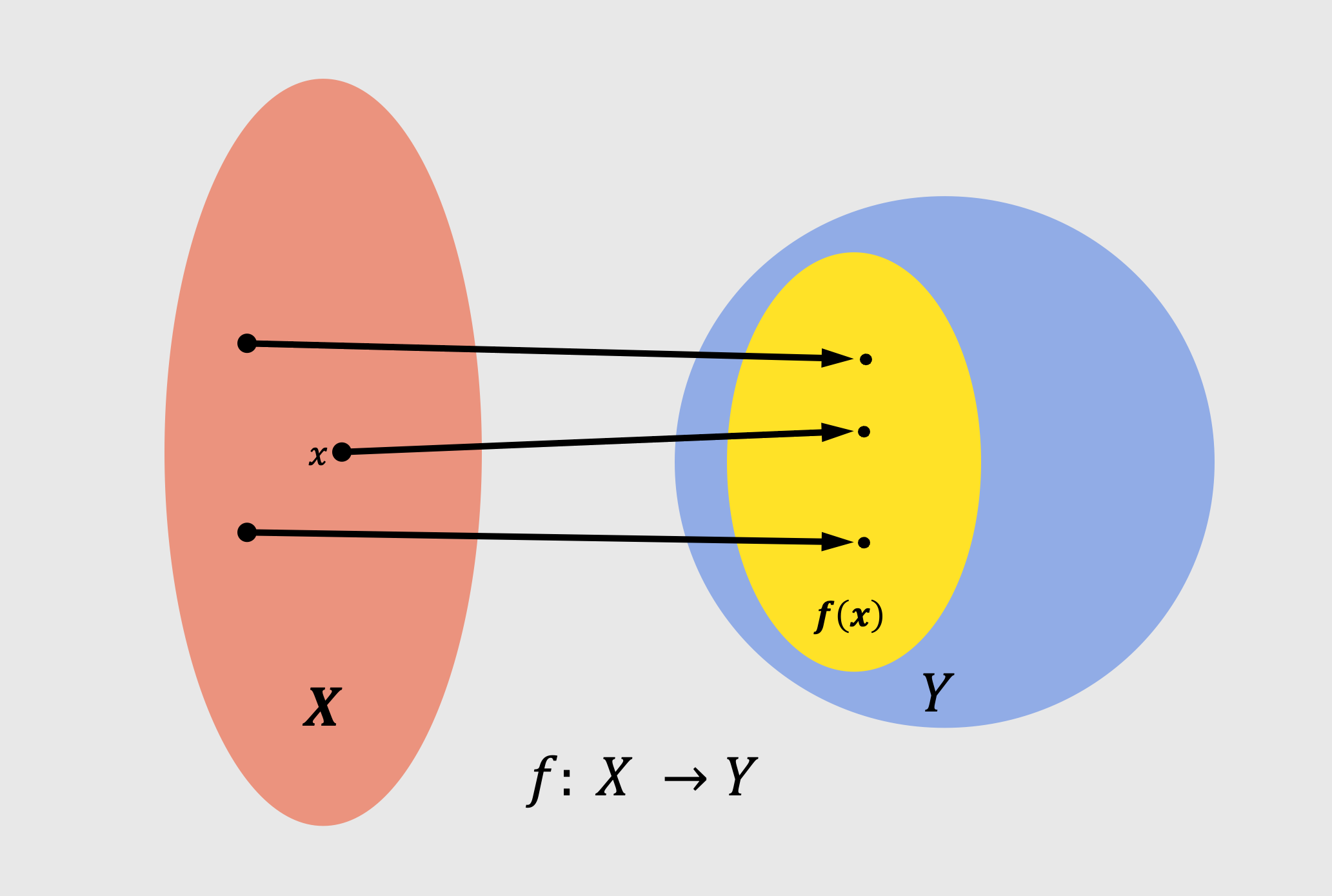
In the previous example, we had as input a single-value variable and output a single-value variable. That is denoted by $f : \mathbb{R} \to \mathbb{R}$. However, there is nothing to constrain us for having a single-value input and output. We can have as input a variable $x$ that has multiple dimensions. The same goes for the output.
We can write thus the following:
\[f:x \rightarrow y\] \[f : \mathbb{R}^{D} \to \mathbb{R}^{M}, \quad x \mapsto y\]with $D, M$ are the dimensionality of the input and output. We can say in other words that we have multi-dimensional (or multivariate) input and output. To understand what we mean with multi-dimensional inputs, we can think of the example of having as a input a vector with multiple features (instead of just one). A simple example of a function could be to take as input a vector variable $\mathbf{x}\in \mathbb{R}^D$ (a vector with $D$ number of features) and do nothing so return the same vector as output, so $\mathbf{y} = \mathbf{x} \in \mathbb{R}^{D}$.
In the tutorial about mathematics for ML we saw multiple types of functions. One simple example is the calculation of dot product in vectors. The dot product of a vector ($\mathbf{x} = [x_1, x_2]^{T}$) could be defined as:
\[f(\mathbf{x}) = \mathbf{x}^{T}\mathbf{x}, \text{ with } \mathbf{x} \in \mathbb{R}^2\]would be specified as:
\[f : \mathbb{R}^{2} \to \mathbb{R}, \quad \mathbf{x} \mapsto x_1^{2} + x_2^{2}\]Visualizing functions
A perfect way to grasp the idea behind the functions is to plot them in the cartesian space and inspect how to actually modify the input space.
The most of the functions that we discuss during the lectures of EoML course are simply mapping : $\mathbb{R} \to \mathbb{R}$ or $f : \mathbb{R}^2 \to \mathbb{R}$. Sometimes also $f : \mathbb{R}^3 \to \mathbb{R}$. We are focusing on these functions since they are easy to visualize. However, as we said before functions can have both multivariate input and output as well.
The following figure has a simple example with mulitple functions ($y = x$, $y = x^2$, $y = x^3$ and $y = 5 \cdot sin(x)$).
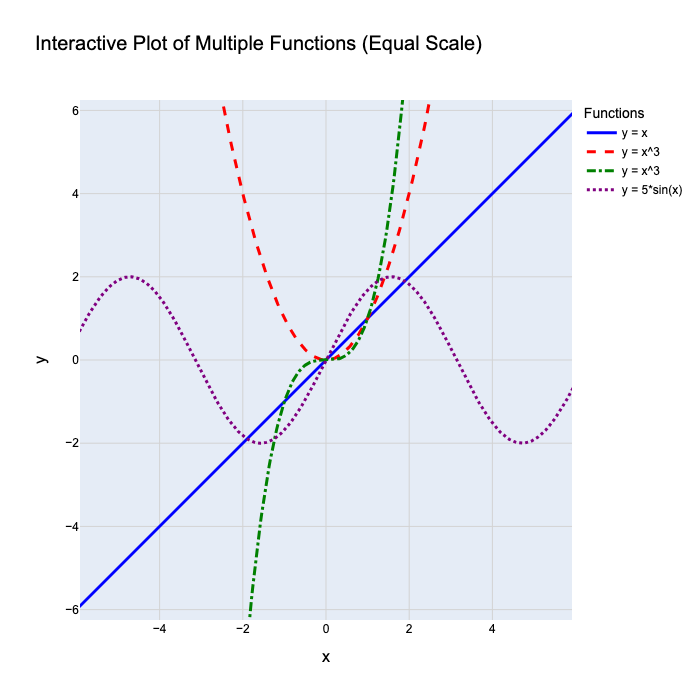
We can see a different example of functions that map input and output $f : \mathbb{R} \to \mathbb{R}$.
Another example is to have as input a two-dimensional input and output a single-value variable. We can have the following example $y = f(x_1, x_2) = x_1^2 + x_2^{2}$. That can be seen in the following figure:
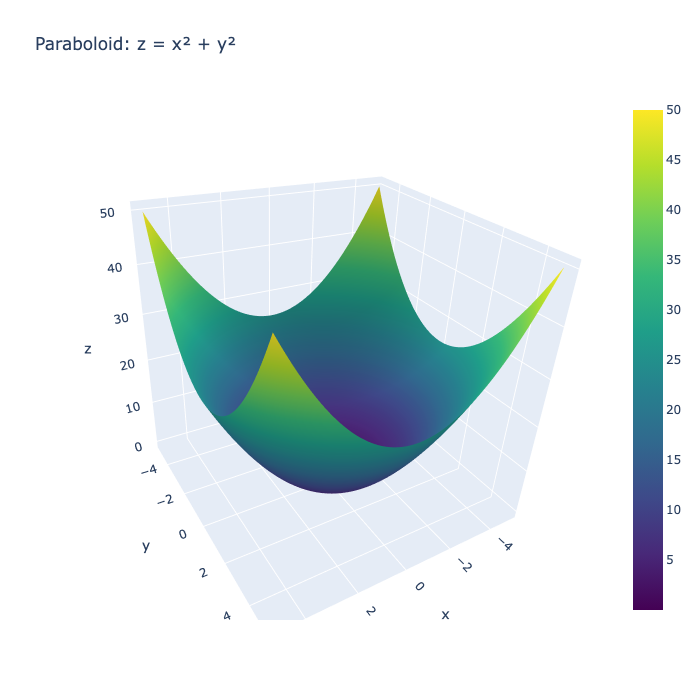
Here $z = x^2 + y^2$. We can see that the how the values of $z$ looks at different location for the pair $x, y$ and that minimum value for $z = 0$ in the location $(x = 0, y = 0)$.
But how can we visualize function that maps high-dimensional input to multi-dimensional output. Unfortunately, that is not possible and we can only visualize functions that have a single-dimensional or two-dimensional input. At the same time, the most of the interesting problems in machine learning has higher dimensionality and we cannot visualize in the same way that we did with previous examples. There are though some tools that can perform dimensionality reduction (which are methods that remove unecessarry information) with which we can still plot things of high dimensionality.
Functions in machine learning context
A really common discussed metaphor in machine learning is that our ML model can be considered as box, or a system or a function, that receive some input and spits out an output. As an example we can consider the problem of regression, where we do have as input our variable $\mathbf{x}$ that represent an instance from a dataset (as an example an image from a dataset with images) and the model $f(\cdot)$ can extract an output $y = f(\mathbf{x})$ is the target feature which continuous value we strive to predict.
Regression setup and error function
A more concrete example in regression is as follows: we have access to data about a specific problem, for instance the House Price Prediction (Real Estate). The input features could be the following:
Features ($x$):
- Size of house (sq. meters)
- Number of bedrooms
- Age of house
- Distance to city center
- Neighborhood quality score
Output ($y$):
- Price of the house
Regression in its simplest version aims find a good fit (the regression function) or a straight line that learns the trend of the input data and can represent this trend. Once we learn this function we can use it to predict new values.
As an example, lets keep our problem as simple as possible, and lets assume that given as input the size of the house we are aiming at creating a predictor that find the price of the house. Thus, our model looks as follows:
\[\hat{y} = wx + b\]so if $x$ represents the size of the house, and $y$ the price of the house, we would like to find the slope $w$ and intercept $b$ that best fit our data. Towards this goal, we can use of an error function or a cost function (or loss function). In the case of regression for instance we set this function to be the mean square error:
Where $y_i$ are the true label of the instances while $\hat{y}_i$ are the predicted values by the regression model. Ideally, we would like to steer and calculate these parameters $\mathbf{w], b$ that minimize the error function and lead to predicted values that are as close as possible to the real-labels of our regression problem. To calculate the ideal parameters we need to use an optimization algorithm to do that.
The loss function can be seen in the following plot (this image is taken from Simon Prince book Understanding Deep Learning):
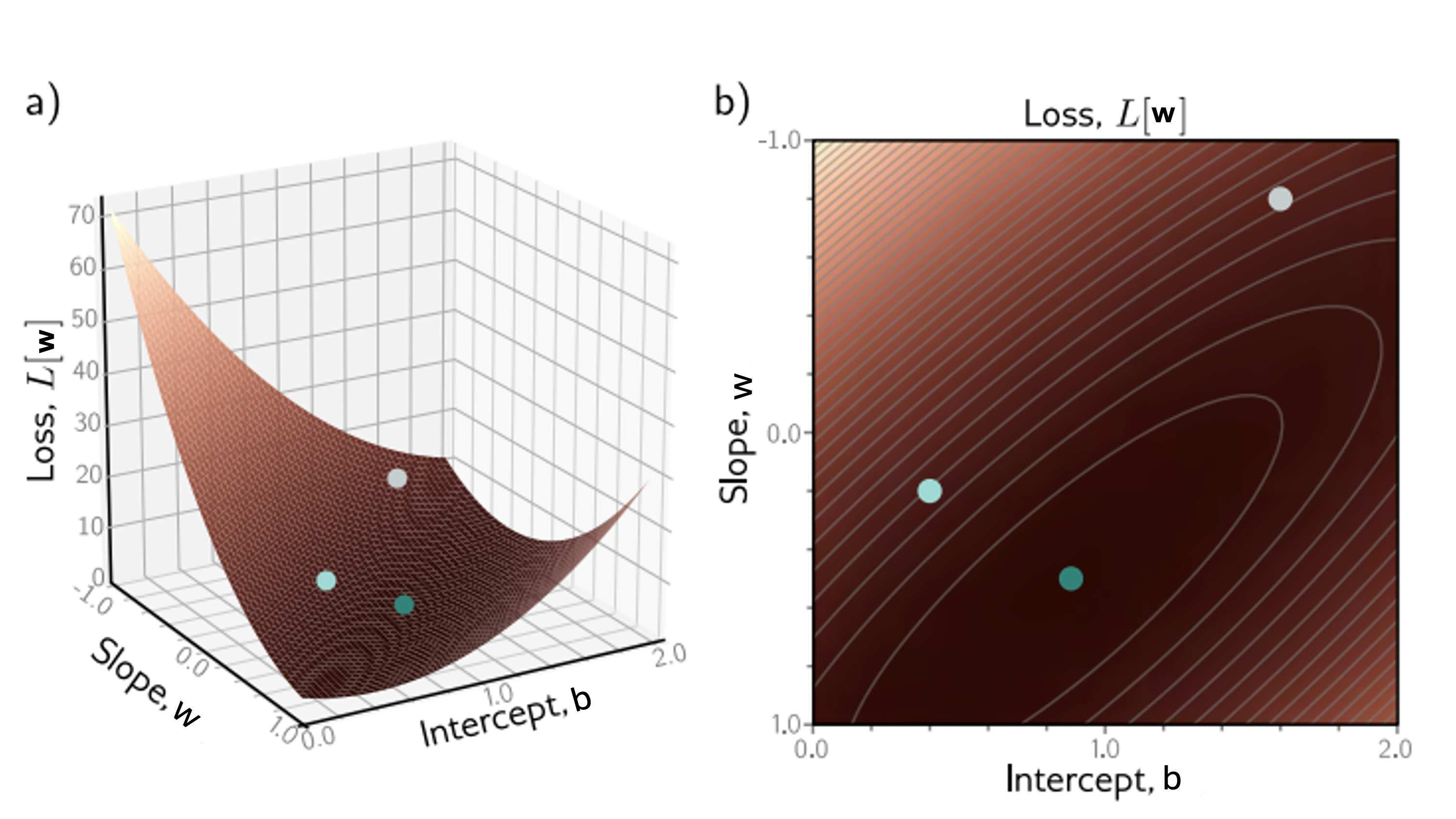
In this figure, we can see the loss function $L(\mathbf{w})$ with respect with parameters $w, b$ slope and intercept. We can see how well different parameters w,b can fit the data with respect to the loss function (error function). Our task when designing an algorithm in ML is to figure out which parameters $w, b$ fit our data with the minimum loss. We can see that the minimum can be found in the green spot (with roughly $w = 0.2$ and $b = 1$).
However, in this example, it was kind of easy to spot that after plotting the Loss over the regression parameters $\mathbf{w}, b$. For more complicated functions, or mutli-variate case, that wont be possible to gauge from a plot and decide where the global minima for a function lies. Thus, we need to find an automatic way to compute the parameters that minimize the loss function. The mathematical tool to do so is called optimization it is based on differentiation. If you wont remember how derivatives and differentiation works fom high-school in the upcoming paragraph we will gently introduce the concepts of optimization and differentiation and gradient.
In principle, to locate the minimum of a function we need calculate the slope of a function everywhere and in the position where this slope is equal to zero it is where we do have an extreme of a function (either a minima or a maxima). We call these extremes critical points or stationary points.
In the upcoming section we will see how we can compute the derivative of a function and how to use it in practice to optimize our problem.
Slope of a function and differentiation of univariate functions
The very first thing that we will analyze is the slope of a function and in particular we will start with the slope of a linear function. What we define as slope in this situation is the rate of change of the linear function that is the same everywhere (no matter what will be the two points that we decided to choose):
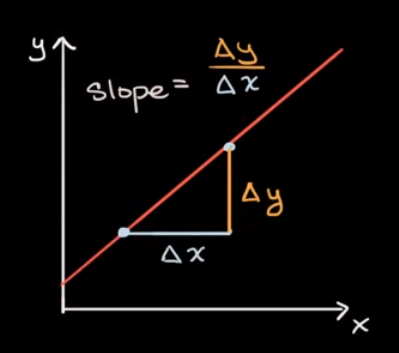
If our linear function looks as follows $y = wx + b$, the parameter $w$ shows to us the slope of this function.
However, the rate of change is not the same when we chose a non-linear functions. In this case, the slope does not remain the same and we cannot compute it in the same way as before.
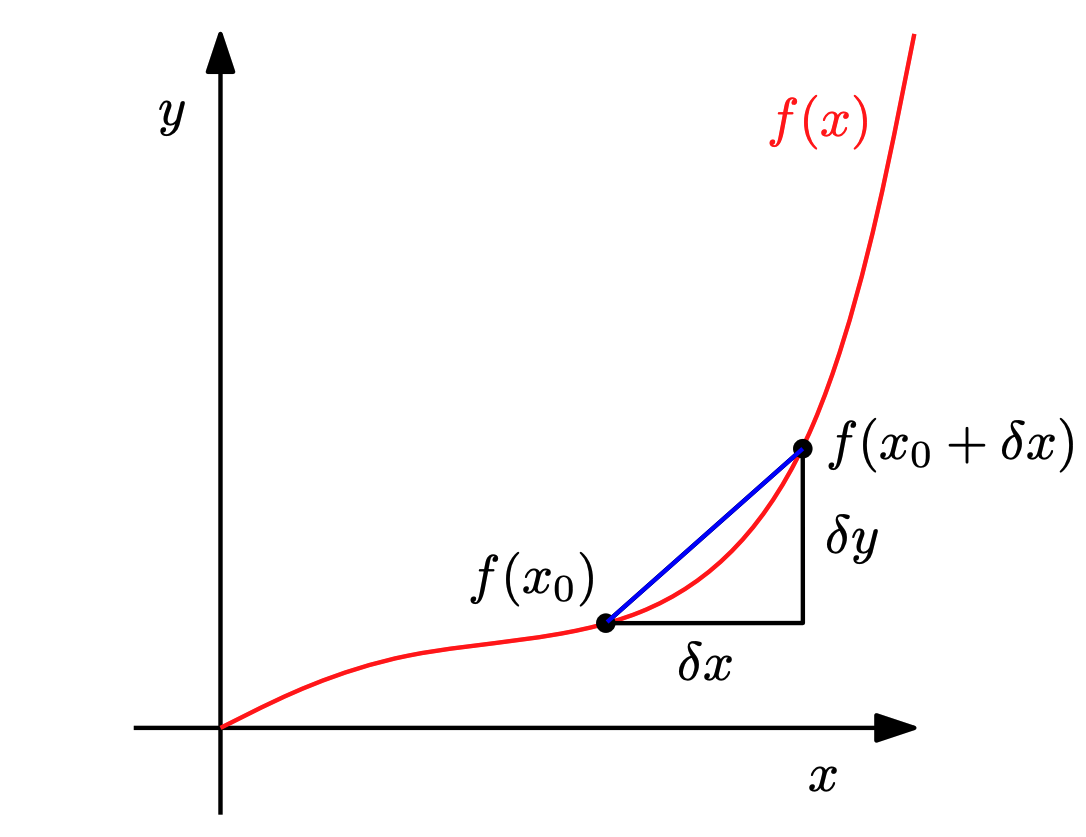
The way to calculate rate of change in this case is as follows: compute the average slope of a function between two points ($\partial x$) using the following formula:
\[\frac{\partial y}{\partial x} = \frac{f(x + \partial x) - f(x)}{\partial x}\]This fraction could be seen as the average slope between $x$ and $x + \partial x$. In the limit where the difference $\partial x$ is close to zero we obtain the tangent of $f$ at $x$. This tangent is called alternatively the derivative of f at x.
The whole idea is that by setting this difference close to zero (using $h = \partial x \to 0$), our non-linear function tends to behave as a linear function, so it can be represented by a tangent linear function which slope now is our function slope but only in this specific location only. More formally, we can denote as derivative the following limit:
\[\frac{df}{dx} = \lim_{h \to 0} \frac{f(x+h) - f(x)}{h}\]As a simple example to understand what is going on is the following: We do have the function $y = x^2$ and we would like to calculate its derivative throughout the input space. In the following image you can see how the function looks like if we plot it in the Cartesian space, but also how does its derivation looks like throughout the Cartesian space:
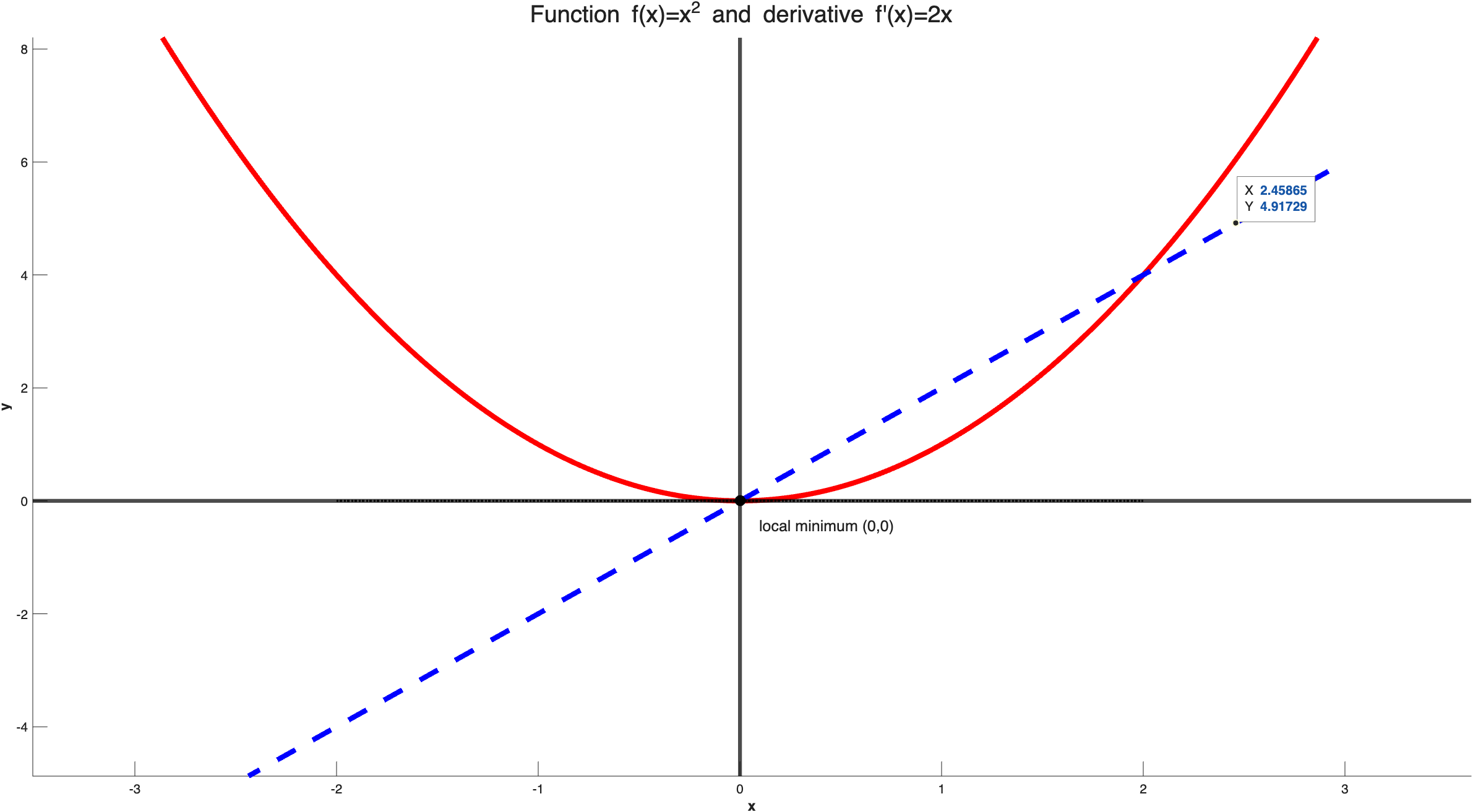
Note, that close to $y = -\infty$ the slope of the function $y$ is big and point towards the negative direction since the value of $y$ tends to reduce and this is the same, then as the function tends to go towards $y = 0$, the slope still has negative values but its size tends to reduced until $y = 0$, where the slope is also $y’ = 0$. Usually, with $’$ we symbolize the derivative of a function. Then, once $y$ goes towards the positive side for $x$ the slope becomes positive and the magnitude of the slope increases.
Thus, by calculating the derivative we calculate the slope of the function that shows in which direction our function is heading to and also the magnitude of the change. When we calculate the derivative of a function, except of finding the slope, we can also spot the local or global extremes of the function which are located in the positions where $f^{‘}(x) = 0$. In our example, $f^{‘}(x) = 0$ is taking place when $x = 0$, thus, we have a global minimum at this position.
In general, for every function $f(\cdot)$, if we would like to find its minimum/maximum, the first thing we need to do is to compute the derivative, set it equal to zero and solve the equation for $x$ to find the point where the function $f(x)$ is minimized or maximized. Note, that these points where the derivative is equal to zero are called stationary points and they show either global or local extremes. That means that they reveal the points $x$ where the $y$ change directions (from being increasing to being decreasing). To grasp this better, we can check the following example:

A lot of things are going on in this figure. There are multiple stationary points where the derivative of $f^{‘}(x) = 0$. We can spot all these points and they are denoted in the figure with the red spots. It is important to note that when computing global maximum or minimum we don’t considered the infinity values as candidates to our problem. Another note is that finding the stationary points does no quarantee that they are either global or that they are minima or maxima. You will need to inspect a bit closer what is happening. However, the take-home message is that these critical points are interesting points that could be at least either global or local extremes and either maxima or minima.
Back on Machine learning
To come back into the Machine learning problem that we defined before, which is finding parameters $w, b$ that minimize the error function $f(x)$, for instance the MSE in case of regression
\[\mathcal{L}_{\text{MSE}}= \frac{1}{n} \sum_{i=1}^{n} \left( y_i - \hat{y}_i \right)^2\]In similar fashion with the previous analysis, we are looking for the stationary points for this functions, so we compute the derivative of the function, we set it to be equally to zero, and then, we solve the equation $f^{‘}(x) = 0$ with respect to $\mathbf{w}$ and $b$ and we cn have an analytic solution for the parameters that we are looking for.
In the case of linear regression it ends up being easy to find this point where the parameters, $w$, $b$ minimize the error function and this point is the following:
\[\mathbf{w}^* = (\mathbf{X}^\top \mathbf{X})^{-1} \mathbf{X}^\top \mathbf{y}\]while for parameter $b$ we do have:
\[b^* = \bar{\mathbf{y}} - \bar{\mathbf{X}}^\top \mathbf{w}^*\]where $\bar{\mathbf{y}}$ and $\bar{\mathbf{X}}$ is the sample mean from our data. The steps finding this solution is not that important, but what is important is that having a dataset with instances and the corresponding target values, we can figure out a way to compute our parameters for the linear regression problem that are based on these data.